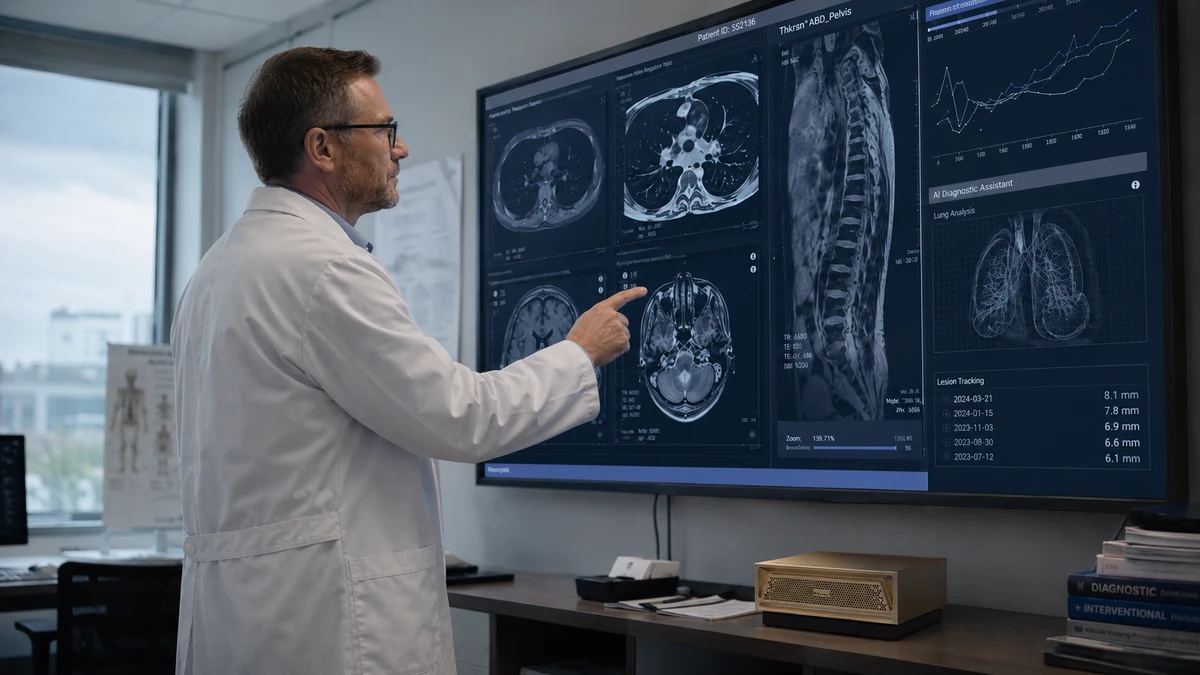
以小见大
向下滚动,探索 MegaCube 的每一面。





01 · 整体外观
铝合金机身,方正之美
航空级铝合金一体压铸,圆角曲面与精密 CNC 细节兼顾工业美学与结构强度。
02 · 前面板
蜂窝散热格栅
前置蜂窝孔阵列精密排布,最大化进气量,让 GB10 芯片持续满血运行。
03 · 后置接口
连接无短板
4×USB Type C · HDMI 2.1a · RJ45@10GbE · 2×QSFP @200Gbps,全部后置,桌面干净整洁。
04 · 形态尺寸
掌心之间
150 × 150 × 50.5 mm,正方形底面,重量仅 1.2 kg,却搭载 1 petaFLOP AI 算力。
05 · 随处部署
随处安放,即刻推理
办公桌、实验室、边缘现场。接通标准电源,无需机房,AI 算力随时就位。